


안녕하세요. Bold9 서버개발팀 박연호 입니다.
N+1문제는 보통 orm에서 발생하는 문제라고 알고 있습니다. N+1이 무엇이고, 어떻게 해결할 수 있는지는 검색하면 관련 자료가 많이 나옵니다.
이 글에서는 N+1자체에 대한 문제보다는, GraphQL의 관점에서 N+1을 바라보면서 왜 발생하고, 어떻게 해결할 수 있는지 알아보겠습니다.
GraphQL resolver가 동작하는 방식
기존의 rest api의 경우 각각의 엔드포인트 마다 반환하는 데이터가 고정적입니다. get /user으로 요청을 보내면 클라이언트는 유저의 email만 필요함에도 불구하고, email, name, addres, …등 모든 정보를 다 가져오게 됩니다. 이를 over fetching이라고 하죠. 반대로 클라이언트가 유저와 유저의 게시글을 조회하고 싶은 경우 /user, /post 총 2번의 요청을 하게 됩니다. 이를 under fetching이라고 합니다. 물론 유저와, 유저의 게시글을 조회하는 엔드 포인트를 만들면 되지만, 모든 케이스에 대하여 엔드 포인트를 만들게 된다면 서버는 더 복잡해질 것입니다.
이런 문제점을 해결한 것이 GraphQL이며, GraphQL을 사용하면 클라이언트에서 원하는 데이터를 입맛대로 조회할 수 있습니다. 이는 클라이언트와 서버가 서로 SDL(Schema Definition Language)라는 인터페이스로 의사소통하기 때문입니다.
type User {
id: Int
name: String
posts: [Post]
}
type Post {
id: Int
content: String
author: User
authorId: Int
}
type Query {
users: [User]
}
Java
복사
서버, 클라이언트가 SDL로 의사소통 하긴 하지만, 사실 SDL은 껍데기 일뿐입니다. 실제로 데이터 처리를 하는 곳은 resolver입니다.
테스트를 위해 미리 DB에 2명의 유저와 유저마다 3개의 게시글을 생성하였습니다. orm 조회 시, 실행되는 log를 볼 수 있도록 설정하였습니다.
const resolvers = {
Query: {
users: (parent, args, ctx, info) => { <-- resolver 함수
return prisma.user.findMany({});
},
},
User: {
posts: (parent, args, ctx, info) => { <-- resolver 함수
return prisma.post.findMany({
where: {
author: parent.authorId,
},
});
},
},
};
Java
복사
query{
users {
name
posts {
content
}
}
}
prisma:query SELECT `test1`.`User`.`id`, `test1`.`User`.`name` FROM `test1`.`User` WHERE 1=1
prisma:query SELECT `test1`.`Post`.`id`, `test1`.`Post`.`content`, `test1`.`Post`.`authorId` FROM `test1`.`Post` WHERE 1=1
prisma:query SELECT `test1`.`Post`.`id`, `test1`.`Post`.`content`, `test1`.`Post`.`authorId` FROM `test1`.`Post` WHERE 1=1
Java
복사
실행되 쿼리를 보면, 처음 Query.users에서 모든 유저를 조회한 후(2개의 유저 조회), 각 유저마다 다시 게시글을 조회하고 있습니다. 즉 GraphQL은 각각의 필드마다 resolver 함수가 달려있고, 실제로 클라이언트에서 필드 요청을 할 때만 해당 resolver 함수가 실행됩니다.
Query.users에서 2명의 유저가 조회되었기 때문에 User.posts가 총 2번 실행되었습니다. 이렇듯 resolver 함수를 클라이언트가 질의했을 때만 동작하며 데이터 기준으로, 즉 조회된 유저 수만큼 posts resolver 함수가 실행됩니다.
GraphQL와 N+1문제
위에서 GraphQL resolver가 어떤 식으로 동작하는지 보았습니다 근데, 자세히 보면 좀 비효율적으로 동작하는 것을 알 수 있습니다.
prisma:query SELECT `test1`.`User`.`id`, `test1`.`User`.`name` FROM `test1`.`User` WHERE 1=1
prisma:query SELECT `test1`.`Post`.`id`, `test1`.`Post`.`content`, `test1`.`Post`.`authorId` FROM `test1`.`Post` WHERE 1=1
prisma:query SELECT `test1`.`Post`.`id`, `test1`.`Post`.`content`, `test1`.`Post`.`authorId` FROM `test1`.`Post` WHERE 1=1
Java
복사
처음 모든 유저를 조회하면서, 2번째 줄부터는 각 유저의 게시글을 조회하였습니다. 만약 유저가 10000명이라면, 실행되는 쿼리의 횟수는 10001번이 될 것입니다.
모든 유저를 실행하는 쿼리 = 1번
모든 유저의 게시글을 조회하는 쿼리 = 10000번
이를 N+1문제라고 합니다. 유저를 조회하는 1번의 쿼리와 모든 유저(N명)의 게시글을 조회하기 때문입니다.
근데, 조금만 더 생각해 보면 굳이 각각의 유저마다 게시글을 조회하는 것이 아니라, where authorId in (id1, id2, ..)으로 한 번에 조회하면 되지 않아? 라는 생각이 듭니다.

select * from post where authorId in('id1', 'id2', 'id3', ...);
Java
복사
네, 당연히 그렇게 하면 됩니다. 하지만 GraphQL은 유저마다 posts resolver가 실행되기 때문에 유저에 해당하는 게시글만 조회할 수 있습니다.
DataLoader
위에서 where authorId in (’id1’, ‘id2’, ‘id3’, …)을 할 수 있는 방법이 DataLoader입니다.
DataLoader를 보면 batch라는 말이 자주 나오는데, 그 뜻을 보면 다음과 같습니다.

DataLoader는 4번 실행되는 GraphQL resolver를 한 번만 실행시켜주는 마법 같은 도구가 아니라, resolver에서 반환하는 값을 캐시에 저장하여 한 번에 DB를 조회하는 방법을 말합니다.
async function batchPosts(authorIds: readonly number[]) {
const posts = await prisma.post.findMany({
where: { authorId: { in: authorIds.map((v) => v) } },
});
const result = authorIds.map((authorId) =>
posts.filter((post) => post.authorId === authorId)
);
return result;
}
const dataLoader = new DataLoader(batchPosts);
const resolvers = {
Query: {
users: (parent, args, ctx, info) => {
return prisma.user.findMany({});
},
},
User: {
posts: (parent, args, ctx, info) => {
return dataLoader.load(parent.id);
},
},
};
Java
복사
prisma:query SELECT `test1`.`User`.`id`, `test1`.`User`.`name` FROM `test1`.`User` WHERE 1=1
prisma:query SELECT `test1`.`Post`.`id`, `test1`.`Post`.`content`, `test1`.`Post`.`authorId` FROM `test1`.`Post` WHERE `test1`.`Post`.`authorId` IN (?,?)
Java
복사
쿼리 결과를 보면 유저의 게시글을 매번 조회하는 것이 아니라 한 번에 조회하고 있습니다. 우리가 원하는 방법입니다. DataLoader으로 위와같 이 처리가 가능한 이유는 캐시와 process.nextTick()을 내부적으로 사용하기 때문입니다.
유저의 posts resolver에서 load 메서드는 parent.id와 promise.resolve를 캐시에 저장하며, promise를 반환합니다. load 메서드에서 캐시된 keys 값은 batchPosts의 인자로 들어가게 됩니다.

유저의 posts resolver가 모두 실행되면 process.nextTick()에 의해 dispatchBatch() 함수가 실행됩니다.
process.nextTick()은 이벤트 루프의 일부가 아니며, 이벤트 루프에서 실행되는 작업보다 먼저 수행됩니다.
node 환경에서는 process.nextTick()를 사용하지만, 브라우저 환경에서는 setImmediate, setTimeout을 사용합니다.

dispatchBatch 함수에서는 기존에 load 메서드에서 캐시한 유저 아이디를 사용하여 위에서 우리가 정의한 batchPosts 함수를 실행합니다. batchPosts 함수는 반드시 promise를 반환해야 합니다.
_batchLoadFn = batchPosts(직접 정의한 함수)
batch.keys = load 메서드에서 캐시한 유저 아이디들
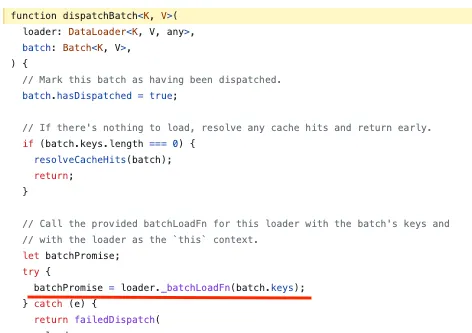
batchPosts에서 캐시된 keys 값(authorId)으로 실행한 후, 그 값은 batchPromise에 넣습니다.
batch.callbacks[]에 authorId를 캐시 하면서 동시에 load메서드에서 반환하는 Promise의 resolve를 같이 캐시했습니다. batch.callbacks[i].resolve(value)를 하나씩 보면…
batch.callbacks[i].resolve = n번째 유저의 posts resolve에서 반환한 promise의 resolve
value = n번째 유저의 게시글 데이터
위의 코드 덕분에 DataLoader에서 유저의 게시글 조회를 일괄처리한다 하여도, n번째 유저의 posts resolve에서 정확한 게시글을 반환하게 됩니다.
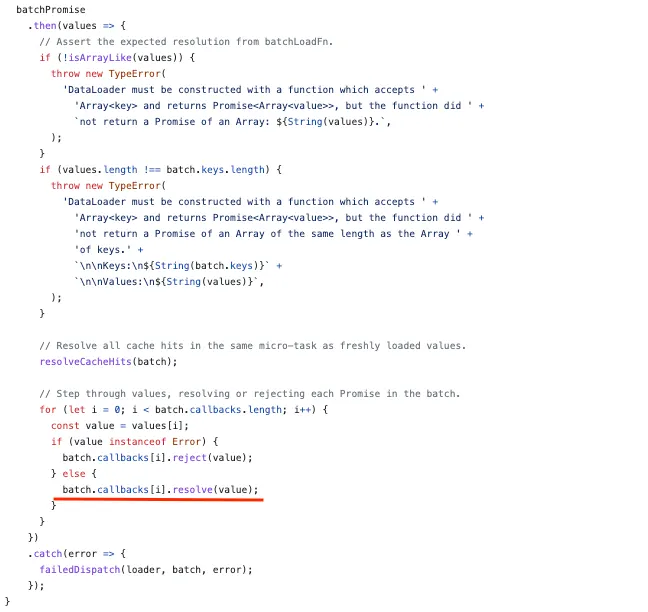
정리하면, resolver에서는 load를 실행하며 load 메서드는 authorId를 캐시하며, 동시에 promise를 반환합니다.
모든 resolver가 종료되면 process.nextTick에 의해, promise가 resolve 되면서 posts에서 유효한 게시글을 받아볼 수 있습니다.
마치며
입사하고 처음 GraphQL이 어떻게 동작하는지 몰랐을 때, DB가 여러 번 조회되면서 왜 그렇게 되는지 의문을 가졌던 적이 있었습니다. 여러 자료를 보면서 GraphQL 동작 방식을 이해하면서 ORM의 N+1문제와 별개로 GraphQL을 사용하면 DataLoader를 무조건 사용해야 하구나 느꼈습니다.
DataLoader를 사용하면서 한 번에 batch 작업을 하면서 어떤 resolver에서 어떤 값을 반환해야 하는지 어떻게 알지? 매번 궁금했는데, 이번 글을 작성하면서 DataLoader 코드를 다시 봤는데 resolve까지 캐시 하는 것을 보고 궁금증이 한 번에 풀렸습니다.